Downloading and studying my message behavior
Published:
Digital privacy is everywhere, and recent laws are pushing companies to disclose whatever personal information they may have on you. In the spirit of science, I’m going to make myself my own study subject and observe what Facebook has stored from my messenger history. Along the way, I’ll do some recursion, a little parallelization, some generators for data procesing, and basic visualization to observe my messenger behavior. Notebooks can be found here, but this one you can’t reproduce because I won’t be providing my messenger data (try this notebook on your own messenger data if you’re curious).
No real conclusion to this memo, but it’s interesting to see firsthand that a lot of data gets preserved from your messages – pictures, gifs, videos, audio, files, emotes, participants, timestamps.
The message data from Facebook is organized like this:
- inbox/
- chat1/
- message1.json
- message2.json
- audio/
- files/
- gifs/
- photos/
- videos/
- chat2/
- message1.json
- chat1/
We can start with some basic tree-walking to identify which is the largest chat group
import os
from pathlib import Path
import json
import multiprocessing
from multiprocessing import Pool
import dask
from dask import delayed
import pandas as pd
import matplotlib
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
def size_of_tree(p):
if 'json' in p.suffix:
with open(p.as_posix()) as f:
message_data = json.load(f)
return len(message_data['messages'])
elif p.is_dir():
return sum([size_of_tree(a) for a in p.iterdir()])
else:
return 0
def parent_function(p):
return {p: size_of_tree(p)}
def parent_function_chunk(p):
return {folder: size_of_tree(folder) for folder in p}
p = Path('/censored/so/you/cant/find/my/facebook/inbox')
all_dirs = [a for a in p.iterdir() if a.is_dir()]
Since this is an embarrassingly parallel situation, we can easily show the serial version is slower than the parallel version (using dask or multiprocessing), with or without some chunking
%%time
sizes = [parent_function(folder) for folder in all_dirs]
CPU times: user 5.3 s, sys: 17.6 s, total: 22.9 s
Wall time: 1min 30s
%%time
all_delayed = [delayed(parent_function)(folder) for folder in all_dirs]
results = dask.compute(all_delayed)
CPU times: user 9.65 s, sys: 1min 4s, total: 1min 14s
Wall time: 30.4 s
%%time
with Pool() as p:
pool_results = p.map(parent_function, all_dirs)
CPU times: user 131 ms, sys: 171 ms, total: 302 ms
Wall time: 27.5 s
%%time
all_delayed = [delayed(parent_function_chunk)(all_dirs[i::6]) for i in range(6)]
results = dask.compute(all_delayed)
CPU times: user 8.13 s, sys: 59.7 s, total: 1min 7s
Wall time: 31.4 s
%%time
with Pool() as p:
pool_results = p.map(parent_function_chunk, [all_dirs[i::6] for i in range(6)])
CPU times: user 242 ms, sys: 33.7 ms, total: 276 ms
Wall time: 28.9 s
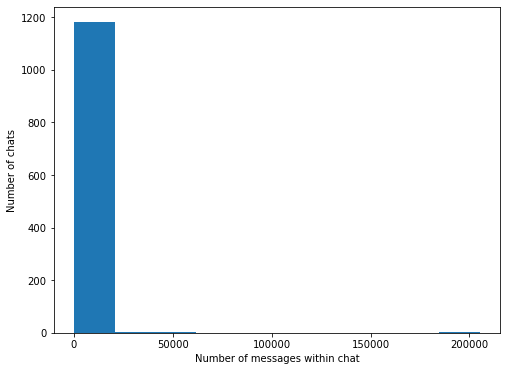
For those curious, I have a pretty skewed chat message distribution…
message_sizes = [size for chunk in results[0] for size in chunk.values()]
fig, ax = plt.subplots(1,1, figsize=(8,6))
ax.hist(message_sizes)
ax.set_ylabel("Number of chats")
ax.set_xlabel("Number of messages within chat")
Text(0.5, 0, 'Number of messages within chat')
fig, ax =plt.subplots(1,1, figsize=(8,6))
ax.hist(np.log(message_sizes))
ax.set_ylabel("Number of chats")
ax.set_xlabel("Log number of messages within chat")
Text(0.5, 0, 'Log number of messages within chat')

We can make a small data pipeline for my message history by using two iterators, one after the other. The first iterator get_json_files_iter is simple, it will just burrow its way through each directory, grab all the json files, and spit out one at a time, returning a generator. The second iterator process_json_iter will take an item from the get_json_files_iter generator and actually process some information. In this case, getting information about the sender, timestamp, and length of message.
from typing import Iterator, Dict, Any, List
import pathlib
import json
from datetime import datetime
def get_json_files_iter(dirs) -> Iterator[str]:
""" For each dir, get the json files """
root = Path('.')
for directory in dirs:
subdir = root / Path(directory)
for jsonfile in subdir.glob('*.json'):
yield Path(jsonfile)
def process_json_iter(json_iter: Iterator[str]) -> Iterator[List[Dict[Any, Any]]]:
""" Given a json file, parse and summarize the message info"""
for jsonfile in json_iter:
with open(jsonfile.as_posix()) as f:
message_data = json.load(f)
for message in message_data['messages']:
yield {
'sender': message['sender_name'],
'timestamp': datetime.fromtimestamp(message['timestamp_ms']/1000),
'n_words': len(message['content']) if message.get('content', None) else None # Some messages have no text
# like an image/emoji post
}
process_json_iter(get_json_files_iter(all_dirs))
<generator object process_json_iter at 0x7f26228366d0>
Getting through all the files (7 gb) isn’t too bad
%%time
extracted_messages = [*process_json_iter(get_json_files_iter(all_dirs))]
CPU times: user 6.01 s, sys: 0 ns, total: 6.01 s
Wall time: 10.8 s
%%time
df = pd.DataFrame(extracted_messages)
CPU times: user 909 ms, sys: 0 ns, total: 909 ms
Wall time: 900 ms
Conveniently, we can pass the generator itself to create a dataframe. This doesn’t provide much speedup, but it helps keep the code concise
%%time
df = pd.DataFrame(process_json_iter(get_json_files_iter(all_dirs)))
CPU times: user 7.42 s, sys: 0 ns, total: 7.42 s
Wall time: 13.7 s
df.columns
Index(['sender', 'timestamp', 'n_words'], dtype='object')
df.shape
(1003527, 3)
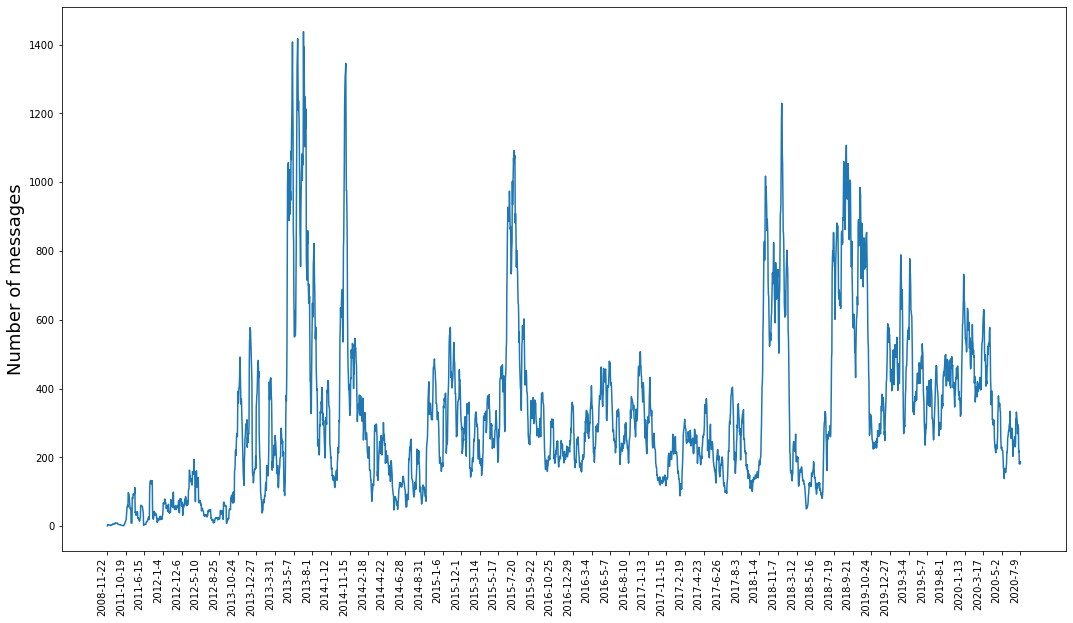
We can look at how my chat history has changed over the years…
df['date'] = df.apply(lambda x: '-'.join([str(x['timestamp'].year),
str(x['timestamp'].month),
str(x['timestamp'].day)]),
axis=1)
grouped_by_date = df.groupby('date').agg('count')
fig, ax = plt.subplots(1,1, figsize=(18,10))
ax.plot(grouped_by_date.index.tolist(),
grouped_by_date['sender'])
ticks = np.linspace(0, len(grouped_by_date.index)-1, num=50, dtype=int)
ax.set_xticks(ticks)
ax.set_xticklabels([list(grouped_by_date.index)[i] for i in ticks], rotation='90', ha='right')
ax.set_ylabel("Number of messages", size=18)
Text(0, 0.5, 'Number of messages')
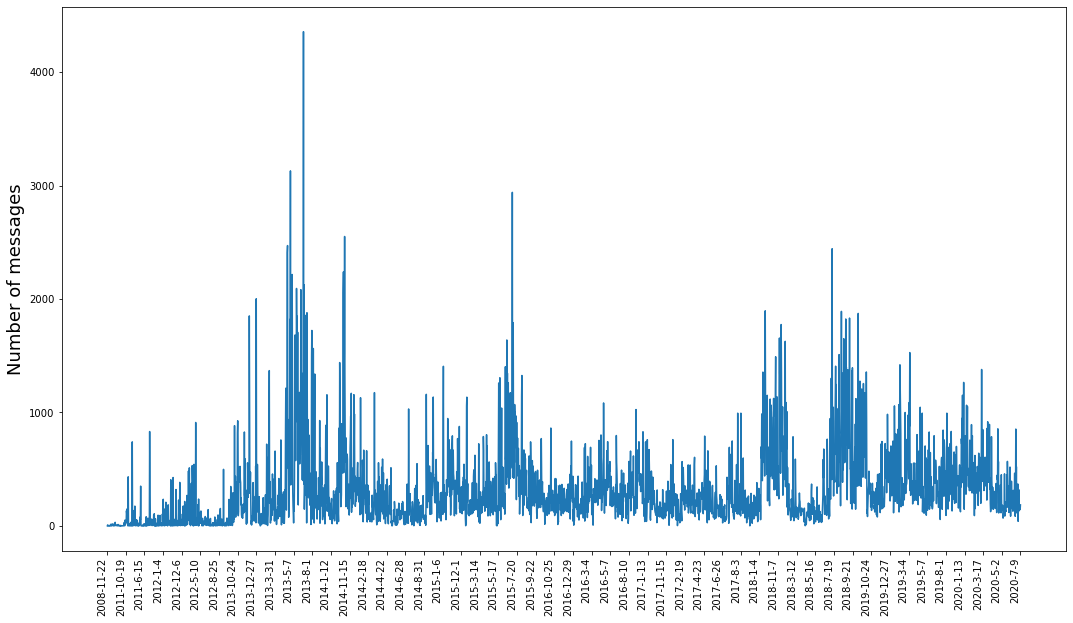
Maybe trying to smooth things out. The timestamps aren’t evenly distributed so the averages could be computed better, but they work well enough for now
rolling = grouped_by_date.rolling(10, min_periods=1).mean()
fig, ax = plt.subplots(1,1, figsize=(18,10))
ax.plot(rolling.index.tolist(),
rolling['sender'])
ticks = np.linspace(0, len(rolling.index)-1, num=50, dtype=int)
ax.set_xticks(ticks)
ax.set_xticklabels([list(rolling.index)[i] for i in ticks], rotation='90', ha='right')
ax.set_ylabel("Number of messages", size=18)
Text(0, 0.5, 'Number of messages')